The GUI text editor gives you a separate panel in the footer to inform you of the number of words, lines, and characters in your text file.
Even though you can easily find the number of strings that occurred in your text file using this GUI text editor, things take a turn when you are talking about the command line.
Here, you cannot find anything in a few clicks; instead, you need to know the commands to find the number of string occurrences in a text file.
So, today you will learn a few ways to count string occurrences in a text file in Linux.
Tutorial Details
| Description | Counting the Word Occurrences in a Text File |
| Difficulty Level | Low |
| Root or Sudo Privileges | No |
| OS Compatibility | Ubuntu, Manjaro, Fedora, etc. |
| Prerequisites | grep, wc, tr, vim |
| Internet Required | No |
Practice Text File
We will use the “file.txt” file located in my home directory with the following content that will be used to show you the examples.
This is a demo file for demonstration purposes to show you
the example of finding a string/char/word occurrence in this file.
In your case, it might be a different file,
so I hope you can apply this to those files on your own.
Thank youSo, let’s find the specific string occurrences in this text file starting with
Using the Grep Command
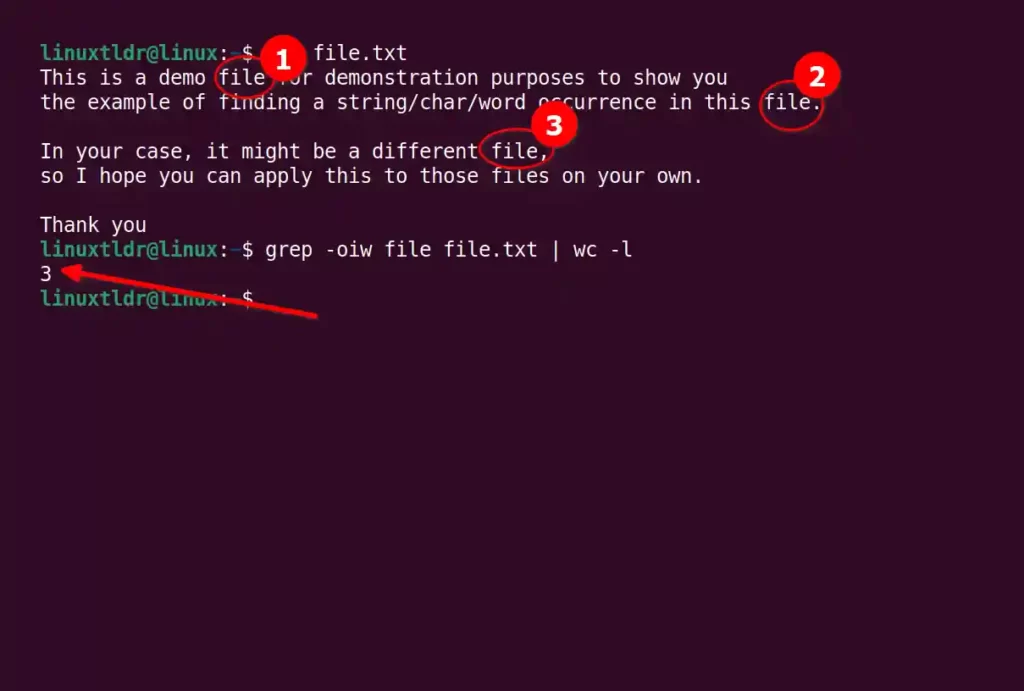
You can use the grep command to count the number of times the “file” string appears in this text file.
$ grep -oi file file.txt | wc -lOutput:
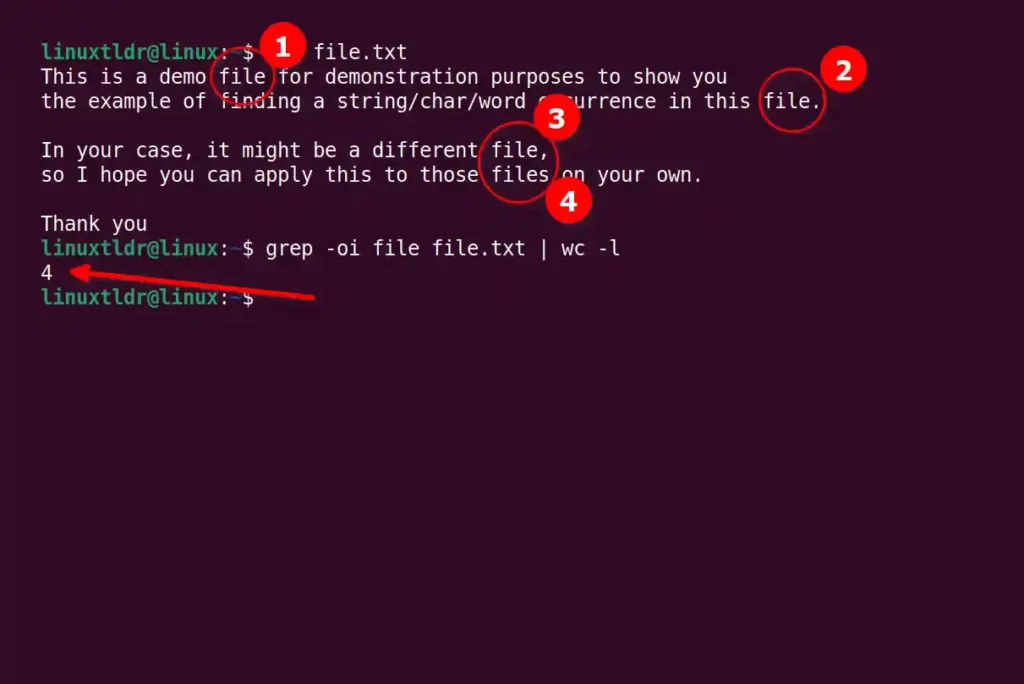
However, if you notice, we search for the “file” string, but it is also counting the “files“, so to search only for the exact match, use the grep command with the “-w” flag.
$ grep -oiw file file.txt | wc -lOutput:
Grep and WC Command Option Breakdown:
| Options | Description |
|---|---|
grep -o | It will count the number of lines that contain the matching word instead of the total number of matches |
grep -i | It will print each match on a separate line |
grep -w | It will only search for the exact line containing matches that form whole words |
wc -l | It will count the number of lines |
Using the TR Command
You can also use the tr command to separate each string into a unique line and then count the number of occurrences using the “grep -c” command.
$ tr '[:space:]' '[\n*]' < file.txt | grep -ic file
4Use the “-w” flag to output only the words that match the whole pattern.
$ tr '[:space:]' '[\n*]' < file.txt | grep -icw file
3Using the VIM Editor
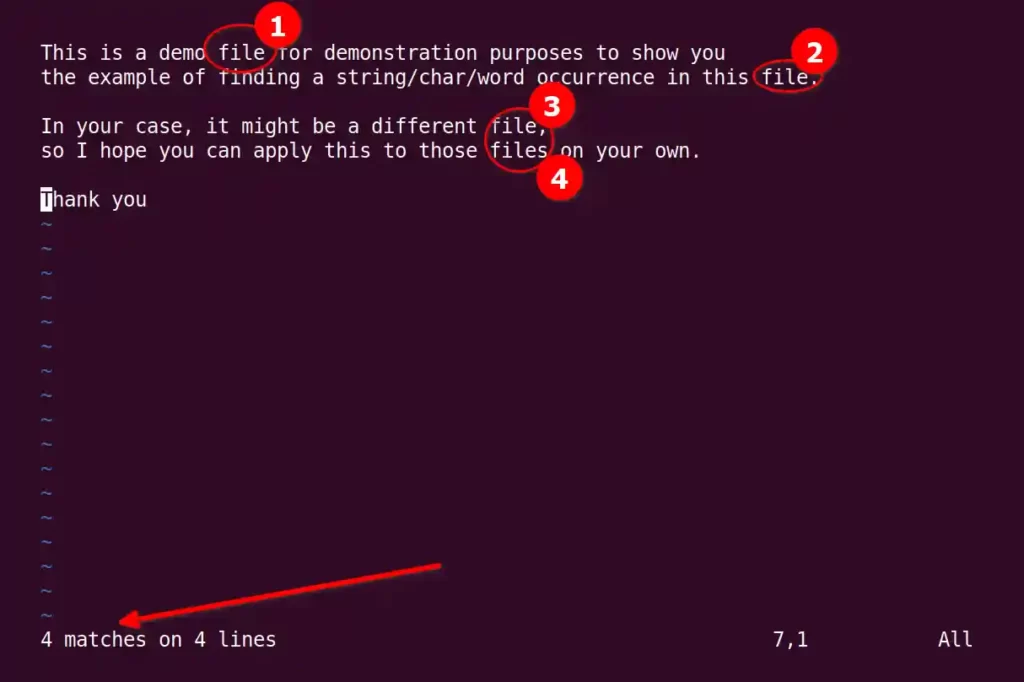
If you are comfortable with the VIM editor, open your file, enter in insert mode, and use the following command.
Syntax:
:%s/pattern//gnFor example, if I want to find “file” string occurrences in my file, I will replace the “pattern” with “file” and press enter to find the total number of occurrences.
And that was the end of this article.
If you have more examples of counting string occurrences in text files, do let us know in the comment section so we can include them.