The Screaming Frog SEO Spider is a powerful and flexible site crawler, capable of efficiently crawling both small and very large websites. The free version allows you to crawl up to 500 URLs, while upgrading to the premium version for $259 per year removes this limit.
It can help you find broken links, audit redirects, analyze page titles and meta data, uncover duplicate content, extract data with XPath, review robots and directives, generate XML sitemaps, visualize site architecture, and much more.
I’ve been an SEO expert myself, and I’ve seen very few people know about or recommend this tool, yet I find it better compared to other premium web-based SEO tools. Obviously, it won’t provide extensive information, but it’s good enough, at least for non-SEOs, to audit their site or investigate their competitors.
In this article, I’ll show you how to install the Screaming Frog SEO Spider tool on Ubuntu and other Linux distros.
Tutorial Details
| Description | SEO Spider |
| Difficulty Level | Low |
| Root or Sudo Privileges | No |
| OS Compatibility | Ubuntu, Manjaro, Fedora, etc. |
| Prerequisites | – |
| Internet Required | Yes |
How to Install SEO Spider on Ubuntu (and Other Linux Distros)
The SEO Spider tool is only available for installation via the distribution package for Ubuntu and Fedora-based distributions, while for Arch and Manjaro systems, you can use the AUR package.
So, if you’re using an Ubuntu-based distribution like Mint, Pop!_OS, or even Debian and Fedora-based ones like AlmaLinux, CentOS, or even RedHat, open your browser and head to the SEO Spider download page to click on the “Download” button.
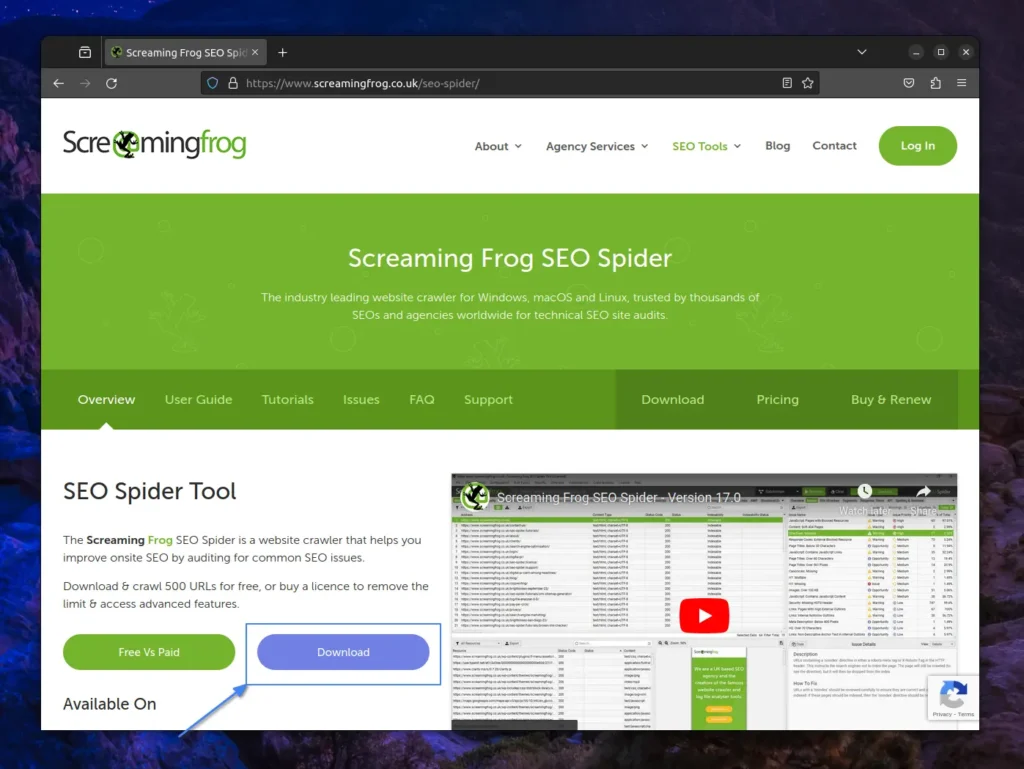
The popup for downloading the latest version of SEO Spider will appear based on your operating system. So, if you are using a Linux system, you will find two options for downloading: “Linux (Ubuntu)” and “Linux (Fedora)“. To begin the download, select the one appropriate for your system.
To find out the Linux distribution you’re using, along with its latest release and codename information, run:
$ lsb_release -a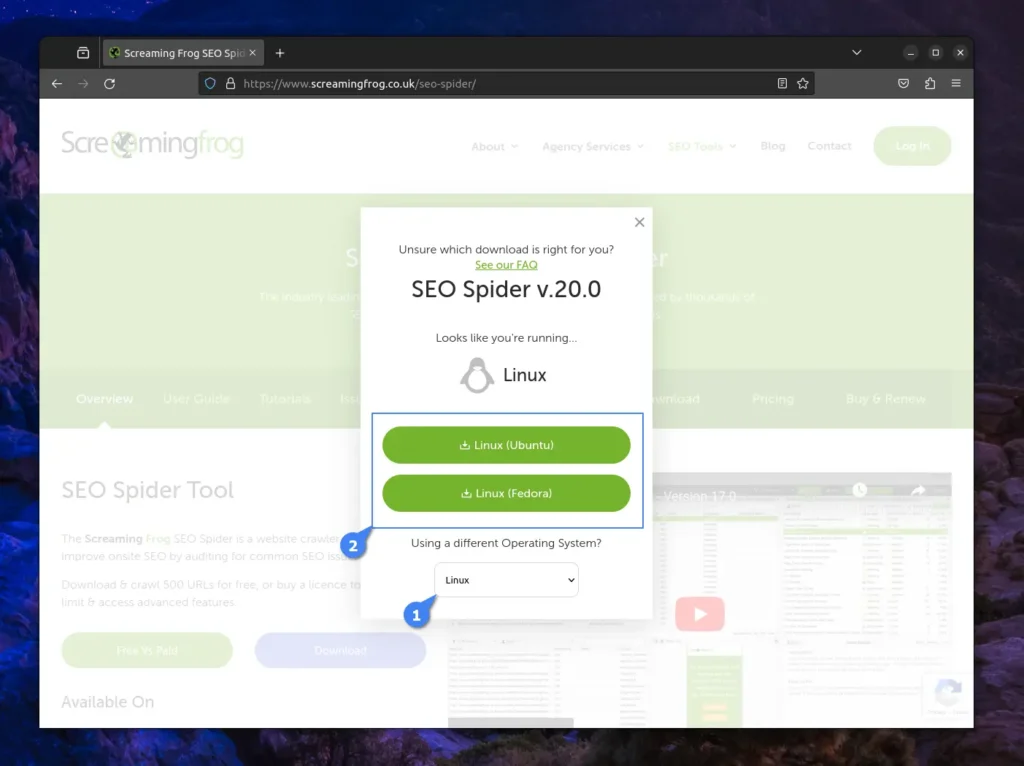
Once the download is complete, the file will be saved to your “~/Downloads/” directory. So, you can open your terminal and navigate to that directory by running the following command:
$ cd ~/Downloads/Output:

Once you’re in the directory, you can use the ls command to list its contents. If your file is fully downloaded, you’ll find it there. In my case, I’m using an Ubuntu system, so I’ve only downloaded the “.deb” package, visible in the attached screenshot above. To install it, or even an “.rpm” package, you can use one of the following commands:
# For Debian, Ubuntu, Mint, Pop!_OS, etc.
$ sudo apt install ./screamingfrogseospider_*_all.deb
# For Redhat, Fedora, CentOS, AlmaLinux, etc.
$ sudo rpm -i ./screamingfrogseospider-*.x86_64.rpmOnce you run the above command, the installation will begin, as shown.
Y” for yes.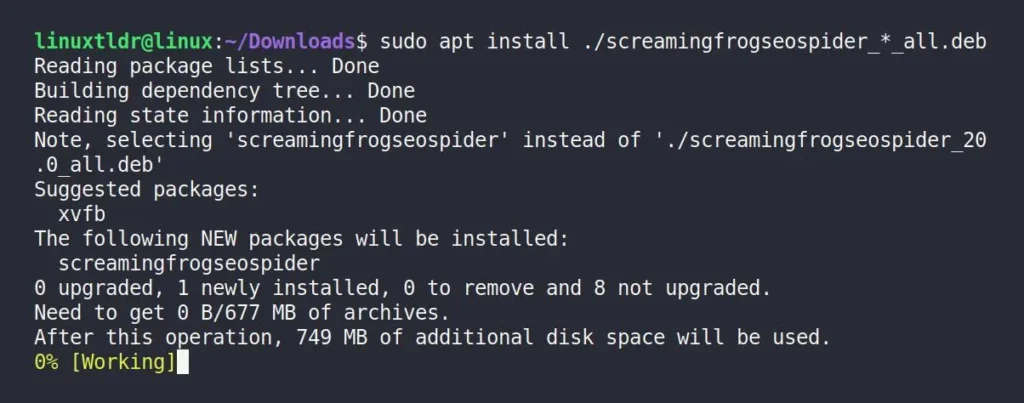
Users using Arch-based distributions like Manjaro, Garuda, or EndeavourOS can also install it using an AUR helper such as Yay by running the following command:
$ yay -S screamingfrogseospiderThat’s it; you can now find it in your application menu.
How to Use SEO Spider on Linux
Once SEO Spider has successfully installed on your selected Linux system, locate and launch it from the application menu.

When you launch it for the first time, it asks you to “Accept” the “End User License Agreement (EULA)“.
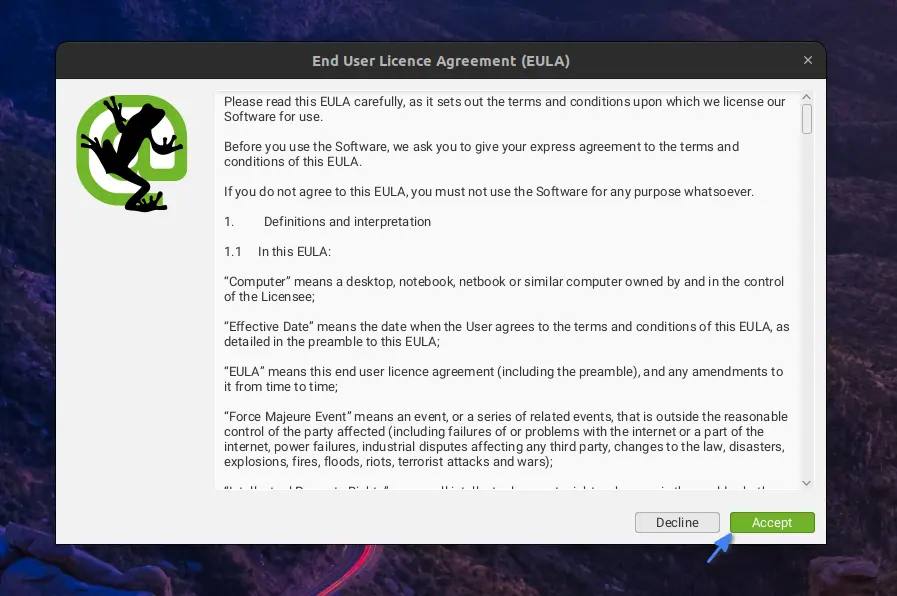
Once done, it will take some time to load important modules like initializing Chromium, installing Node.js, and setting up the main window. Upon finishing, you’ll see the Screaming Frog SEO Spider main window, as shown.
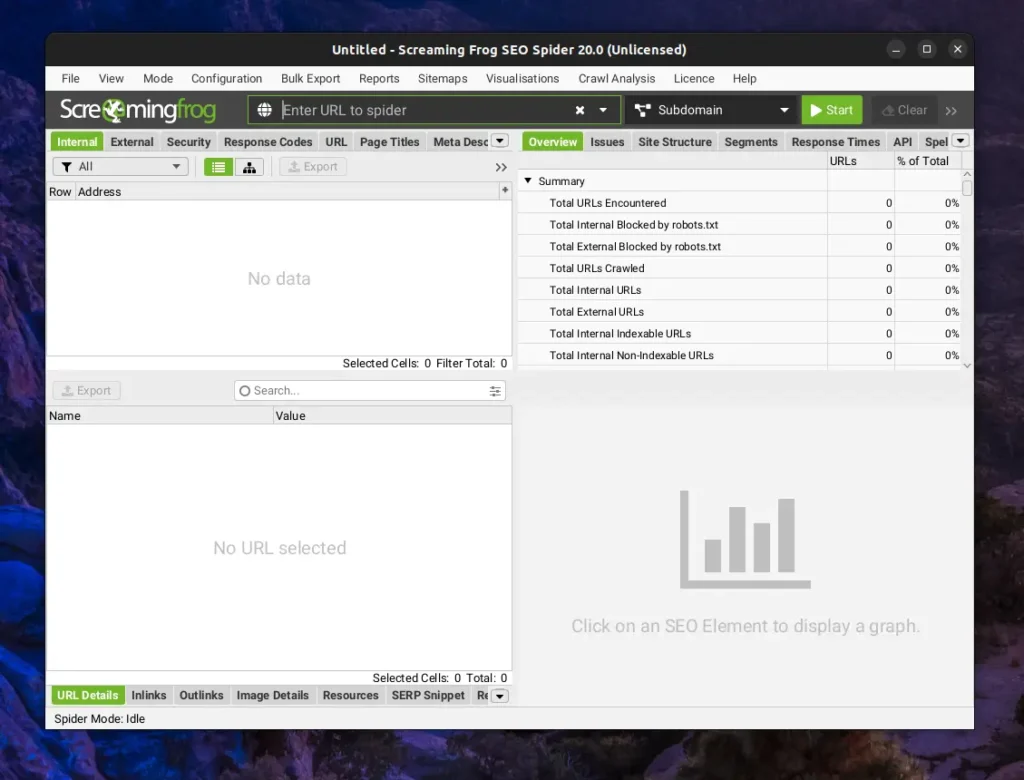
Looking at the title bar, you can tell that I’m using the free version of SEO Spider, which is fine for beginners. To begin, enter your or your competitor’s URL in the URL field and click the “Start” button. It will take some time to crawl the website, depending on your system performance and website size. You can monitor the progress on the bottom right side.
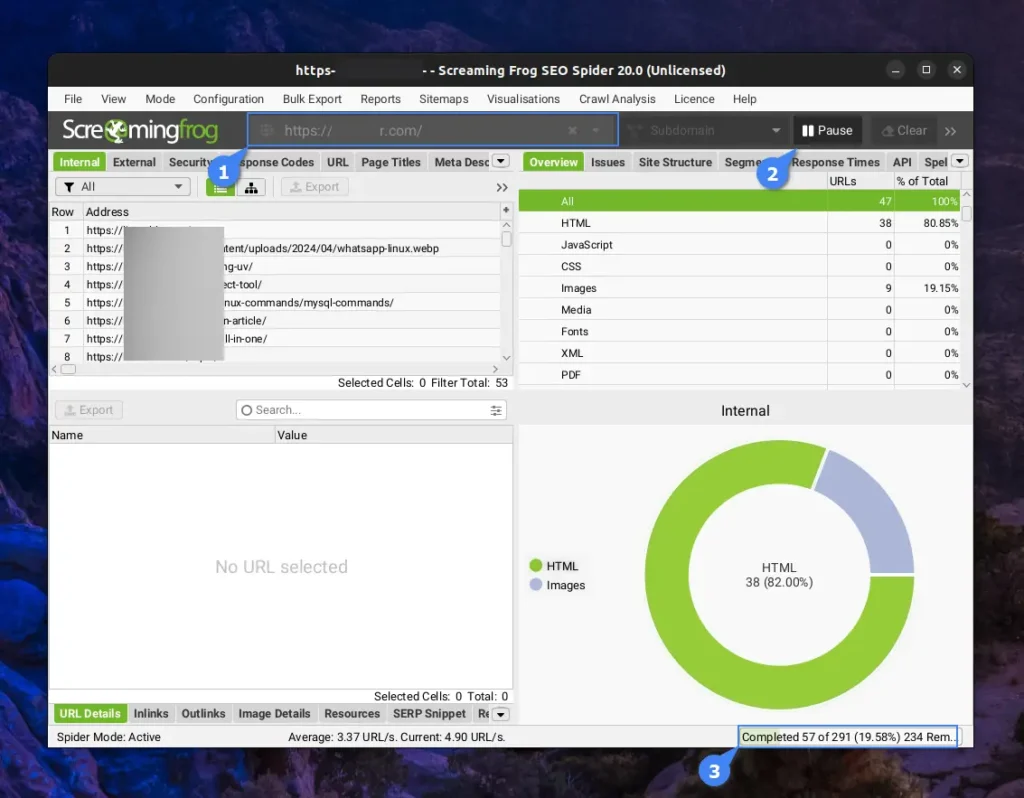
If the size is smaller than 500 URLs, then it will complete the process of crawling without any issues. Otherwise, prompt a “Crawl Limit Reached” status. In both cases, you can check the complete or limited information of the website once crawling is finished by using different filters or going through different tabs.
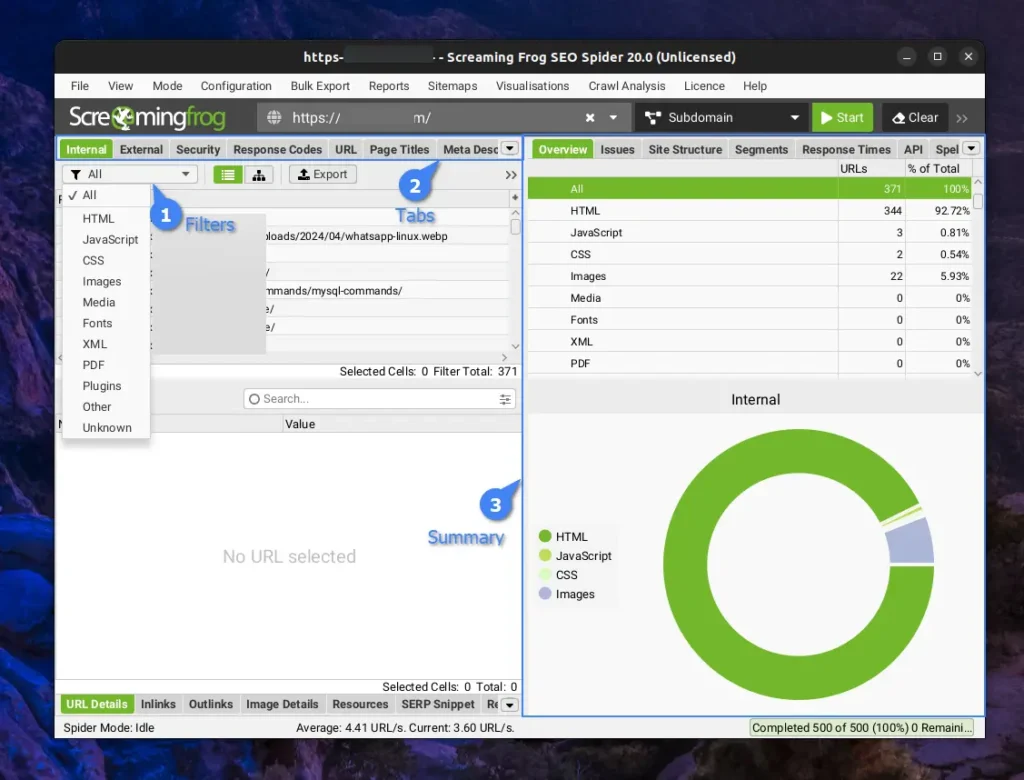
If you’re somewhat knowledgeable in SEO, you can effortlessly navigate through these filters, tabs, etc., to analyze various metrics of the website. Typically, I use an SEO spider to find broken URLs, orphan pages, incorrect or missing titles and descriptions, and a few other issues.
As it’s a bit unpopular among SEOs, you may find it difficult to find learning resources, but don’t worry; the official site has its own user guide that I strongly suggest you follow by clicking this link. So, let’s finish this article by showing the removal steps…
How to Remove SEO Spider from Linux
If you’re not a fan of this tool and wish to uninstall it, no problem! Just run the appropriate command for your Linux distribution.
# For Debian, Ubuntu, Mint, Pop!_OS, etc.
$ sudo apt remove screamingfrogseospider
# For Redhat, Fedora, CentOS, AlmaLinux, etc.
$ sudo dnf remove screamingfrogseospider
# For Arch, Manjaro, Garuda, EndeavourOS, etc.
$ yay -R screamingfrogseospiderFinal Word
The Screaming Frog SEO Spider is an excellent tool for SEOs that I recently discovered, and honestly, I’m using it multiple times a week. I’m surprised it’s not receiving the attention it deserves. If you have more tools like this, let me know in the comment section.
Till then, peace!