They are not that easy to comprehend in one sentence, but for simplicity, you can think of buffers as a way to store file metadata (permissions, location, etc.) during I/O operations for efficient transfer. While cache is used for storing actual file contents in memory to speed up future retrieval.

What are Buffers and Caches in Linux Memory?
Perhaps you’ve all come across the terms “buffer” and “cache” at some point, and some of you might be wondering about the difference between the two.
If you look at their definitions, you’ll notice they share a similar philosophy but differ in terms of functionality.
Definition of 🧾 Buffer: A buffer is a temporary storage area in computing that holds file metadata information like permissions, location, etc. during I/O operations. Buffers are extensively used in numerous aspects of computing, such as networking, I/O operations, and visual processing. [1]
Definition of 📦 Cache: Cache memory temporarily holds frequently used information and programs, providing faster data access for the CPU, as server RAM is slower and located further away from the CPU. A cache hit speeds up data retrieval, enhancing system efficiency.
As you can see, both are used to store temporary but different types of data to speed the process, like I/O operations or for CPU optimizations.
But what is exactly the difference between them? To know more, let’s dig deeper.
Difference Between Buffer and Cache in Linux Memory
To understand the difference between these terms, let’s begin to fully understand what exactly buffer and cache [2] are.
What is 🧾 Buffer?
Buffers are the disk block representation of the data, which contains the metadata information of the files or data during the data transfer from one place to another that is stored under the page caches.
When a data request is made in the page cache, the kernel first checks the data in the buffer, which contains metadata that points to the actual files or data in the page caches, serving as an intermediary.
It usually follows sophisticated management strategies, such as first in, first out (FIFO) and first come, first served (FCFS), for buffering.
What is 📦 Cache?
A cache stores often-used data or instructions to speed up future requests by keeping copies in the kernel, specifically within the RAM, to enhance disk data access and improve I/O performance, basically providing faster access to data than the original source.
The data that will be cached is determined using complex algorithms, and modern CPUs provide a built-in mechanism for this task. Of course, you do not have to enable them separately; they’re preconfigured for your system.
It usually follows sophisticated management strategies, such as least recently used (LRU) or least frequently used (LFU), to decide which data to keep in the cache and which data to evict when the cache is full.
Comparison of Buffer and Cache
Here’s a side-by-side comparison of cache and buffer in tabular format to give you more insights:
| Feature | Buffer | Cache |
|---|---|---|
| Purpose | Temporarily holds data during transfer between two processes or components to facilitate efficient data transfer. | Stores frequently accessed data or instructions to improve data retrieval speed. |
| Content | Holds data exactly as it is received. | Stores frequently accessed data or instructions. |
| Management | Typically follows a FIFO or FCFS strategy. | Uses complex algorithms (e.g., LRU, LFU) to decide what to cache. |
| Access Speed | Does not necessarily provide faster access than the source. | Provides faster access to data than the original source. |
| Usage Examples | Data transferred between a hard disk and memory may be buffered. | Web browsers cache web pages for quick loading. |
| Storage Location | Temporary storage in RAM or other memory locations | Typically in high-speed memory (RAM or SSD) |
| Access Control | Managed by the system and sometimes by applications | Managed by the system or applications |
| Size | Buffer sizes vary depending on the use case but can also be smaller than main memory or storage. | Cache sizes are relatively small compared to main memory or storage. |
| Latency Reduction | It helps mitigate latency by optimizing data transfer. | Reduces latency by storing frequently accessed data closer to the CPU. |
| Common Usage in Linux | Used in I/O operations such as reading and writing to and from storage devices. | File system caches and page caches are examples. |
I hope their terminology and differences might be clear to you now. Let’s check out some practical examples on our Linux system to better understand them.
Understanding Buffer and Cache with Examples
You can monitor and manage the buffer and cache usage in Linux using various tools like “free“, “top“, and “vmstat“. These tools provide information about memory usage, including buffers and caches.
To see a better estimation of how much memory is really free and used by buffer or cache, run:
$ free -mhOutput:

Command breakdown:
-m: show output in megabytes-h: show human-readable output
If you look at the above picture, you will find the system has around 8 GB of RAM, of which 1.1 GB is used by the current running process, 46 MB for shared memory, and 2.7 GB is used to store buffer and cache.
Linux uses so much memory for disk cache to prevent RAM from going to waste. Keeping the cache means that if something needs the same data again, there’s a good chance it will still be in the cache in memory. [3]
Accessing data from there is approximately 1,000 times faster than retrieving it from the hard disk; if it’s not in the cache, the hard disk needs to be read anyway, but no time is lost in the cache scenario.
Q.1: What if you want to run more applications?
When you need to run resource-intensive applications that require more memory, your system will dynamically allocate the required memory to them by reclaiming it from already cached resources.
Q.2: Why do top and free show that most RAM is already consumed if it isn’t?
To understand why the top or free directly shows the complete size used to store buffer or cache data, it is to make it easier for the user to understand the memory consumption in their system [4].
To properly understand this, you need to become familiar with terms like occupied, used, free, and available in Linux, which are shown in the following table:
| Memory that is used by | You’d call it | Linux calls it |
|---|---|---|
| Running applications | Occupied | Occupied |
| Buffer and Cached | Used | Used (and Available) |
| Rest of the Memory | Free | Free |
So, in layman’s terms, the memory used by buffer and cached might show in the free command output that they are used, but behind the scenes, they are also available, but only when there is demand.
Q.3: From where does the data shown in the top or free command come from?
The actual data that top and free commands show comes from the “/proc/meminfo” file, a special kind of file in Linux that provides detailed information about the system’s memory usage and statistics.
/proc is a special file system used to store information related to running processes.You can directly read this file using the cat command to get information about your system memory.
$ cat /proc/meminfoOutput:
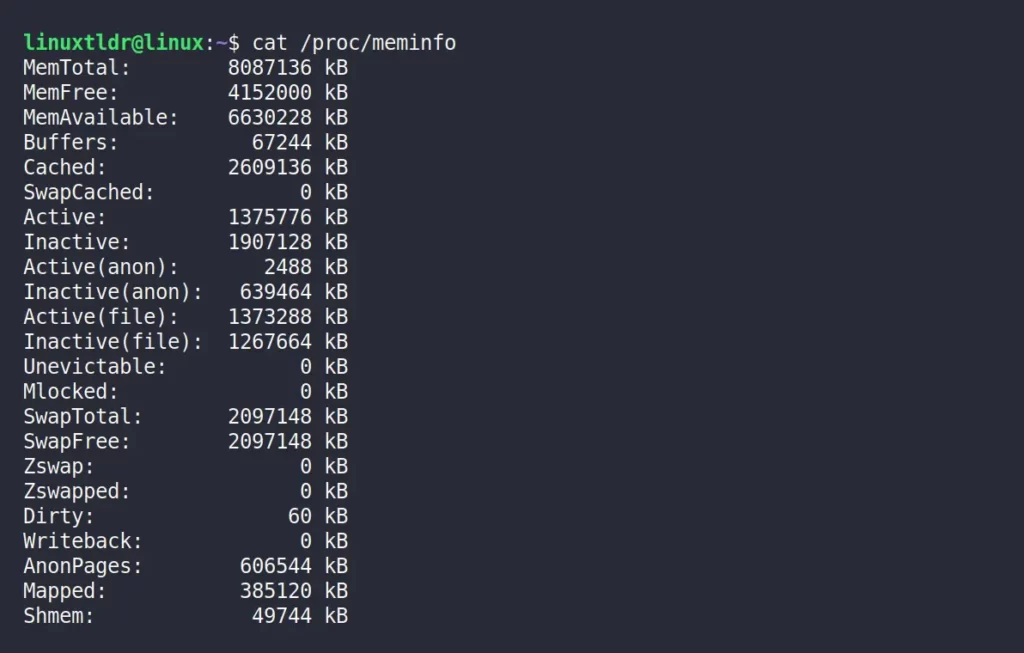
The values in “/proc/meminfo” are reported in kilobytes (KB), and you may need to interpret and analyze them in conjunction with other system monitoring tools and commands to get a comprehensive view of memory usage.
This data is often used by system administrators and developers to check the status of memory resources and identify potential issues related to memory utilization for diagnosis.
Demonstration of Buffer and Cache Working in Linux
At this point, you understood that the buffer is used to cache data that is about to be written, while cache is data that is already stored or cached in memory and used for reading data from files.
But there is a twist: buffer can also be used for reading, and cache can also be used for writing. Let me explain with an example.
Experimenting with Buffer
To begin, open your terminal and start with an empty cache. You can clear the filesystem cache using the following command:
$ free -mh
$ echo 3 > /proc/sys/vm/drop_caches
$ free -mhOutput:
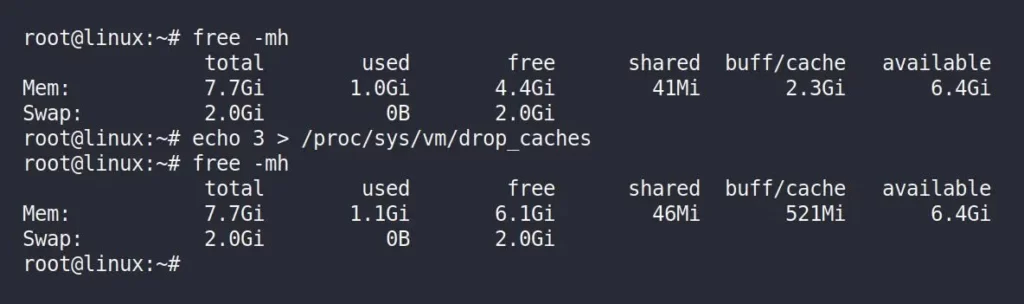
The command “echo 3 > /proc/sys/vm/drop_caches” is used to clear cached data in the Linux kernel’s page cache. Whereas “3” means it clears both the page cache and the slab cache.
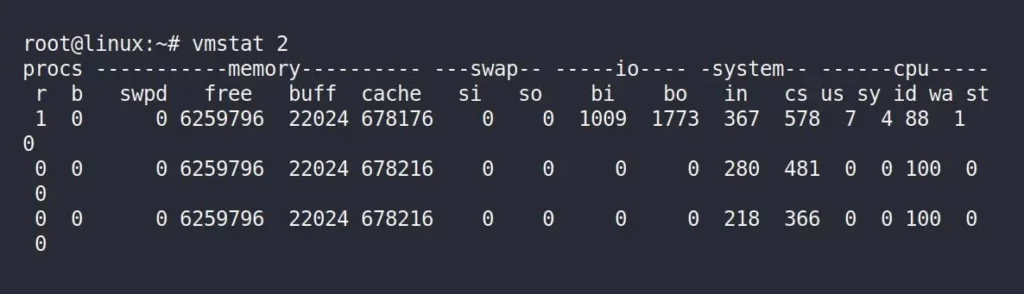
Now, run the following “vmstat 2” command in the same terminal window to monitor and display system performance statistics related to virtual memory at regular intervals (2 seconds in this case).
$ vmstat 2Output:
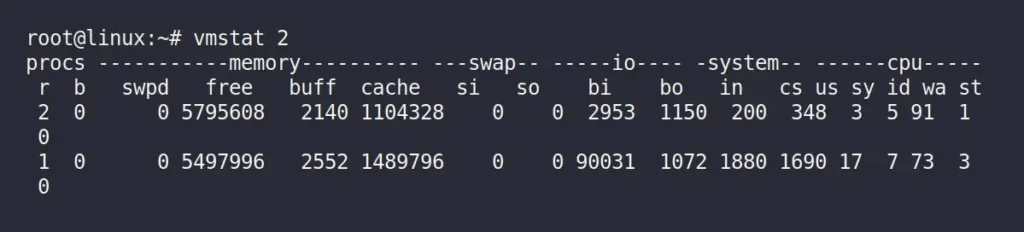
In the above picture, you have to only focus on the “buff”, which stands for buffer, and the “cache“, which stands for cache column, and the unit is measured in KB.
You can launch another terminal window or tab and run the following dd command to create a demo file that will perform read and write operations in different locations:
$ dd if=/dev/sda3 of=/dev/null bs=100M count=500Output:

Now, immediately switch back to your previous terminal windows, running the “vmstat 2” command, and observe the changes in the “buff” column.
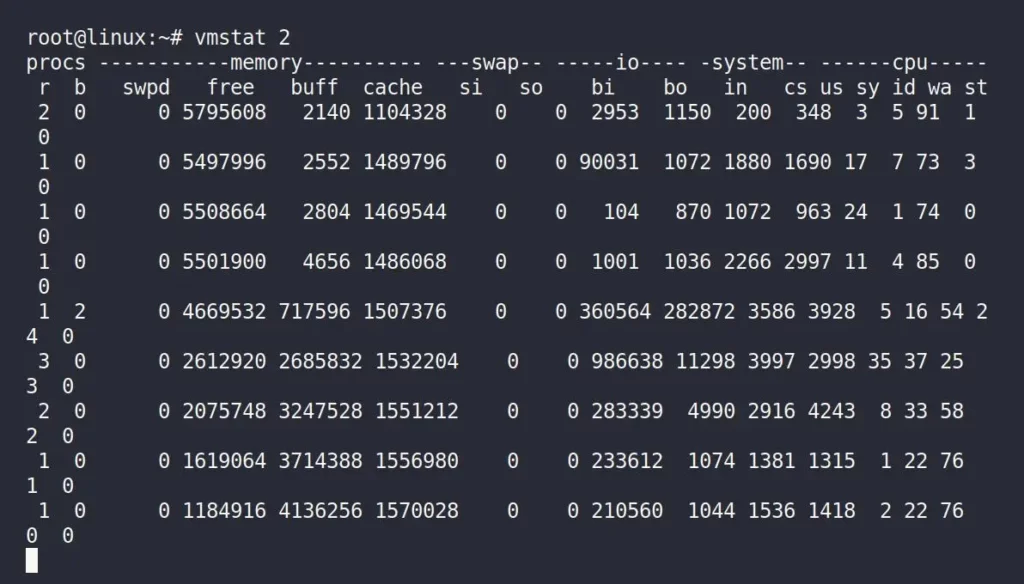
When you examine the “buff” and “cache” columns, you’ll notice that while using the dd command to read the disk, both the buffer and cache sizes increase, but the buffer experiences significantly faster growth.
Experimenting with Cache
For this experiment, again open a new terminal window or use the existing one to clear the filesystem cache using the following command:
$ free -mh
$ echo 3 > /proc/sys/vm/drop_caches
$ free -mhOutput:
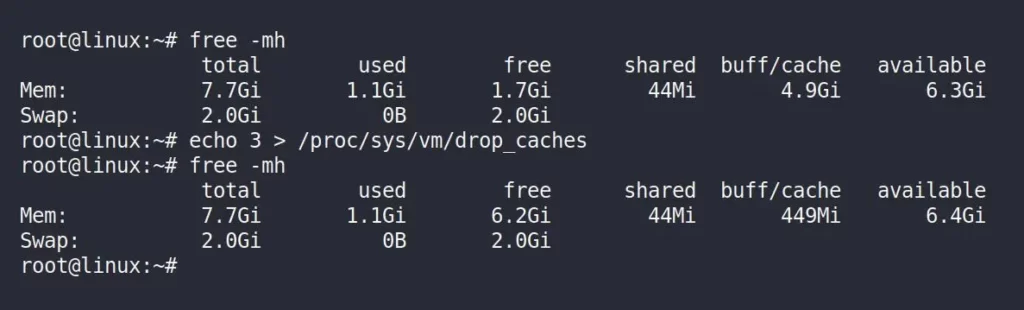
Now, run the following “vmstat 2” command in the same terminal window.
$ vmstat 2Output:
In the above picture, you have to only focus on the “cache” column, launch another terminal window or tab, and run the following command:
- Also Read: What is /dev/zero in Linux and its Uses
$ dd if=/dev/zero of=testfile bs=100M count=500Output:

Now, immediately switch back to your previous terminal windows, running the “vmstat 2” command, and observe the changes in the “cache” column.
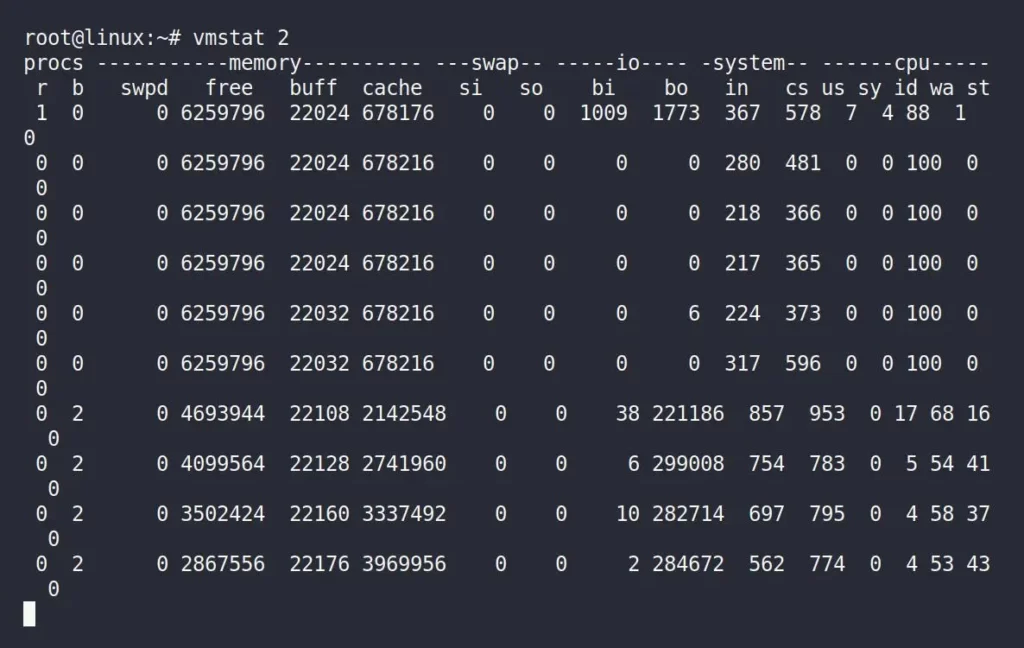
By observing the “cache” column, you find the dd command kept performing read and write operations in the memory while the “buffer” remained unchanged.
Meaning, when reading from the disk, data is stored in the buffer, whereas reading a file results in data being stored in the cache.
Final Word
In simple words, you can understand that a buffer is something that can cache data that needs to be written or data that will be read from the disk. While cache is used to cache files that are being read or written.
I hope this difference is clear to you. If you have any questions, queries, or find any corrections that need to be made, then let us know in the comment section.
Till then, peace!